Teil 2/3
ChatGPT kann Entwicklerinnen in der Angewandten Informatik potenziell Arbeit abnehmen. Das gilt insbesondere für die Arbeit an Wissensgraphen (kurz: KG – Knowledge Graph) und Ontologien. Wie gut ChatGPT und andere große Sprachmodelle das können, hat ein Forschungsteam um Lars-Peter Meyer am Institut für Angewandte Informatik (InfAI) e.V. an der Universität Leipzig untersucht. Dazu hat das Team ein Benchmarksystem für RDF-Knowledge-Graphen aufgesetzt. Das Benchmarksystem heißt LLM-KG-Bench und ist das erste System für diesen Anwendungsbereich. Das System überprüft automatisiert, wie gut ein Sprachmodell (kurz: LLM – Large Language Model) bestimmte Aufgaben ausführt. Es ist daher geeignet, um Sprachmodelle langfristig zu evaluieren, wie Lars-Peter Meyer und Johannes Frey im Poster-Track der Semantics 2023 in Leipzig vorgestellt haben.
Die Forschenden haben zunächst drei Sprachmodelle getestet: Claude-1.3 von Anthropic sowie ChatGPT-3.5 und ChatGPT-4 von OpenAI. Weitere Modelle lassen sich bei Bedarf einfach ergänzen. Die Modelle sollten je drei Aufgaben lösen:
- Fehlerbehebung in vorhandenen kleinen Wissensgraphen
- Extraktion von Datenblättern
- Erstellung von Datensätzen
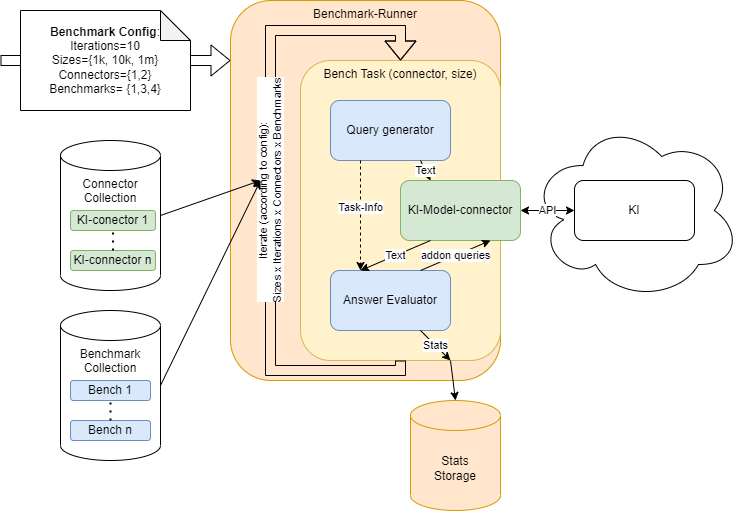
Alle drei Aufgaben gehören zur Entwicklung von Wissensgraphen.
Im Ergebnis hat sich gezeigt, dass die getesteten LLMs noch deutlichen Verbesserungsbedarf für eine zuverlässige Verwendung haben, wie Lars-Peter Meyer einordnet: „Wir sind wohl noch nicht an dem Punkt, wissensgraph-spezifische Aufgaben einfach und ungeprüft an Sprachmodelle abzugeben. Zurzeit liefern sie noch nicht zuverlässig richtige Ergebnisse. Aber wenn sie soweit sind, bekommen wir es durch den LLM-KG-Bench mit.“
Die mit dem Benchmarksystem erstellte Bewertung kann zum Beispiel den Einsatz von Chatbots unterstützen. Chatbots sind LLMs mit Anwendungsoberfläche. Ein Beispiel dafür ist der Bot der 3D-Druck-Plattform Semper-KI. Der Bot führt mit den Nutzenden einen Dialog in natürlicher Sprache. Dabei fragt er die relevanten Informationen ab, um einen Druckauftrag auszulösen. Außerdem erfasst er, in welchem Kontext das gewünschte Produkt steht, zum Beispiel wofür es eingesetzt wird, welchen Belastungen das Teil ausgesetzt ist, ob es sich um ein architektonisches Modell oder um ein Zahnimplantat handelt.
Diese Aspekte kann das LLM abfragen, weil es mit einem Wissensgraph auf Basis der Semper-KI-Ontologie, verknüpft ist. Die Ontologie bildet eine Art maschinenlesbares Nachschlagewerk. Das Nachschlagewerk ermöglicht dem LLM, spezifische Informationen zum 3D-Druck aus dem Wissensgraphen abzufragen. Je nachdem, was die Person, die den Chatbot benutzt, einträgt, reagiert das LLM. Große LLMs wie Chat-GPT sind in der Regel sehr mächtig, unterliegen aber auch den Regeln ihrer Hersteller, in diesem Fall OpenAI. Um Veränderungen des LLMs seitens der Hersteller frühzeitig zu bemerken und regelmäßig automatisiert zu überprüfen, kann das Benchmarksystem eingesetzt werden.
Zum Paper: https://github.com/AKSW/LLM-KG-Benchhttps://github.com/AKSW/LLM-KG-Bench